| Parallel architecture | |
Von Neumann is the basic architecture which most modern day computers use. However there are a number of different architectures which are used for various purposes. One the most popular is known as a parallel architecture. There is a family of different architectures related to this and they can be classified through Flynn's taxonomy. This is a basic categorisation of architectures, including the Von Neumann architecture.
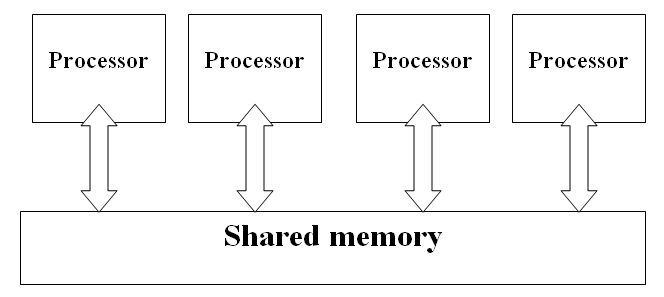
Von Neumann falls into the SISD category as it only has a single processor and a single (shared) set of data. The one we shall continue to discuss is the MISD type of computer. This is where you have multiple processors in a single computer and shared memory across all processors. Note that there multiple could be any number greater than 2. Dual core processors are not exactly parallel architectures however they do fall under the MISD category. This will be looked at later. access to a shared memory unit. That means that each processor can read and write to all available memory.
There are a number of uses of parcel architectures of this kind. These can be broken into two different categories. Processing based and task based. Task based systemsTask based systems are where you have a large number of tasks to perform. Each task would be run on a single processor. However a task could be given to any processor to run. The technique is commonly found on servers. Let's look at a web server. A web server will have a large number of requests sent to it over a period of time. A lot of these requests will come in simultaneously. If there was only a single processor then the server would have to deal with them one after the other by building a queue. However when multiple processors are used the web requests will be delegated out to all available processors. Each processor will have its own queue and there will be an algorithm in place to decide which processor the next request should go to. The algorithm used to choose which processor the next request should go to can be simple or complicated. A simple idea would be to use a round robin approach. The more complicated approach would be to monitor the load on each processor and send the request to the least loaded processor. Considering some requests will be more complicated than others, this approach is what is commonly used on these types of servers. The advantages of this use of architecture is that more requests can be dealt with quickly without having to change the programming of the software. It is much simpler to set up and program for. The biggest disadvantage is that if you have a relatively low number of complicated requests, then most of your processors will remain idle for most of the time. Processing basedThis is where you have a single job to do which involves a high degree of processing power. For example rendering 3d animation for films such as Shrek or Toy Story. In these situations the job will be split up into manageable chunks. For example each processor will calculate a different frame of the animation. The processing of a single task is split up in order to make the full processing of the task quicker. The biggest advantage is obviously a huge increase in the time taken to produce the result. However the biggest disadvantage is that programming such systems is a very difficult task. The coordination of such a system requires very specific programming skills which are normally in short supply in the ICT industry. Most importantly, due to the complexity of the systems, bugs are much more common and harder to track down. Which processor caused the error, when did it happen and is the error repeatable? |
|

| Links |
 Custom Search
Custom Search