
Efficiency in algorithms
The secret behind a lot of improvements in computing is down to more efficient algorithms. A algorithm can be called more efficient if, given the same input, it takes less time to complete a task than a similar less efficient algorithm. It is important to state that both algorithms will give the SAME result just one will be quicker than the other.
Sorting a list of numbers is a classic example. There are many different ways to do this. Two of the most common ways are known as bubble sort and quick sort (these will be covered in detail next year). Bubble sort and quick sort will both arrange a list of numbers into numeric order. They both can handle the same amount of data the only difference is how quickly they do it.
Look at the estimated times for bubble sort and quick sort -
Size of input |
Bubble sort |
Quick sort |
10 |
100 |
10 |
100 |
10, 000 |
200 |
1000 |
1, 000, 000 |
3000 |
10, 000 |
100000000 |
40000 |
10, 000, 000 |
100000000000000 |
500000 |
100, 000, 000 |
10000000000000000 |
6000000 |
The difference between times, initially, is not too big. However as the input gets bigger the difference gets much more significant. The chart below shows this. Due to the sizes of the values I have had to use logarithmic scaling but it does not change the rate at which bubblesort grows against quicksort.
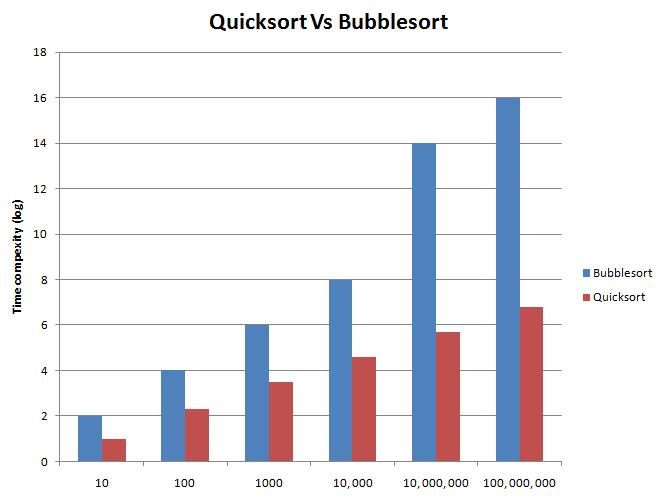
So why even have bubble sort? Why not just use quick all of the time? The answer to this question is not straight forward. The most basic answer is to do with development. Quick sort is a much more complicated algorithm to bubble sort so if we have small input sizes then it would make sense to use the one which is easier to program. Also algorithms do not always perform as well as we would like. There are certain situations where they do not work very well and these are know as worst case scenarios. In these cases the time needed to complete is much higher. So if your input is likely to regularly have the worst case scenario for quick sort then we gain no benefit from using the more complex algorithm.
This area of computing is known as complexity theory and it measures the best, worst and average time case for a algorithm. A lot of really important developments have come about due to complexity theory. For example cryptography works only because it is very difficult to calculate the key . It is known as a NP-complete problem which means that the algorithm which solves the problem is exponential so the problem gets exponentially more difficult the bigger the input gets.
What you need to known is that some algorithms will perform better under different circumstances. Also that the complexity of development is a factor when deciding on which algorithm to use. Finally you should be aware of the average values you will get and the approximate size.
